Il livello Trasporto.
Bibliografia:
Computer Networking. Cap. 3. Autori: James F. Kurose (University of Massachusetts, Amherst) Keith W. Ross (Polytechnic Institute of NYU).
Principi di controllo della congestione.
Nelle sezioni precedenti sono stati esaminati i principi generali e i meccanismi specifici del TCP per offrire un servizio affidabile in previsione che la rete possa perdere pacchetti. Nella pratica, la perdita dei pacchetti potrebbe essere causata da una sovrascrittura dei pacchetti nei buffer dei router, quando la rete è congestionata. La ritrasmissione di un pacchetto risolve un effetto della congestione della rete (la perdita di un segmento del livello trasporto), ma non risolve la causa della congestione: molti computer tentano di trasmettere dati alla massima velocità.
In questa sezione si considera il problema del controllo della congestione in un contesto generale. Si individueranno le conseguenze negative della congestione e si osserverà come si manifesta ai processi del livello applicativo, in modo da adottare le misure necessarie per evitare o prevenire la congestione della rete.
Cause e "Costi" della Congestione
Per studiare il fenomeno della congestione della rete, si propongono tre casi, in ordine di complessità crescente, in cui avviene la congestione della rete. In ciascuno dei casi proposti si individueranno le cause e i costi della congestione (in termini di risorse sottoutilizzate e degrado delle prestazioni osservate sui sistemi terminali). Non si tenterà di trovare soluzioni per uscire dalla congestione o per prevenirla, ma ci si limiterà a capire cosa succede quando gli host aumentano la frequenza di trasmissione dei pacchetti e provocano la congestione della rete.
Caso 1: due trasmettitori e un router con buffer di dimensione illimitata
Si consideri il caso più semplice. Due host (A e B) hanno una connessione verso altri host attraverso uno stesso router.
L'applicazione nell'Host A invia i suoi dati sulla connessione (consegna i dati al livello trasporto attraverso un socket) alla velocità media di λin byte/sec. Questi dati sono originali, nel senso che attraversano il socket solo una volta. Il livello Trasporto incapsula i dati in un segmento e li invia, senza applicare nessun controllo sugli errori o un controllo sul flusso o sulla congestione. Quindi l'host A consegna un traffico al router alla velocità di λin byte/sec. L'host B opera in modo simile e si suppone che invii i suoi dati alla stessa frequenza di λin bytes/sec. I pacchetti dagli host A e B attraversano il router e vengono smistati sullo stesso canale di capacità R. Quando la frequenza dei pacchetti entranti supera la capacità del canale di uscita, nel router si forma una coda di pacchetti in attesa di essere smistati. Si assume che il router abbia memoria sufficiente per immagazzinare i pacchetti entranti. Per questo esempio si assuma che il router abbia una memoria di dimensione illimitata.
 |
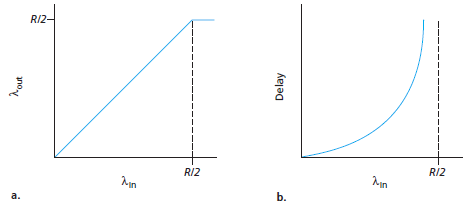 |
La Figura precedente mostra due grafici. Il grafico di sinistra descrive l'andamento del flusso dei dati per connessione (numero di byte al secondo) giunti al ricevitore, in funzione del tasso di pacchetti generati da un trasmettitore. Si ricordi che per ipotesi i due host condividono la capacità R del canale e generano pacchetti con la stessa velocità, quindi R/2 byte/sec appartengono ad un host e R/2 byte/sec appartengono all'altro. Per una frequenza di pacchetti trasmessi compresa tra 0 e R/2 il flusso al ricevitore è uguale al flusso dei pacchetti generati - ogni pacchetto inviato viene ricevuto con un ritardo finito. Quando il tasso di generazione dei pacchetti supera R/2, la capacità del canale non consente di smistare più di R/2 (byte/sec). Questo limite del flusso è una conseguenza della condivisione della capacità del canale tra le due connessioni. I due host non potranno mai superare il flusso R/2. Potrebbe sembrare che raggiungere un flusso per connessione di R/2 rappresenti un pieno sfruttamento della capacità del canale, perchè completamente utilizzato per consegnare pacchetti a destinazione. Il grafico di destra, comunque, mostra la conseguenza che si potrebbe avere operando in prossimità della capacità del canale. Quando la velocità di trasmissione tende ad avvicinarsi ad R/2 (per valori crescenti), il ritardo medio tende a raggiungere valori sempre più elevati.
Quando la velocità di trasmissione supera R/2, il numero medio dei pacchetti nella coda di uscita del router cresce sempre più, ed il ritardo medio tra sorgente e destinazione tende a infinito. (ammettendo che le connessioni mantengano queste velocità di trasmissione per un tempo infinito e che la memoria dei router, dove vengono memorizzati i pacchetti entranti da smistare, sia infinita). Quindi, operando a velocità prossime alla capacità R del canale, si ha il massimo utilizzo ma un ritardo di consegna dei pacchetti inaccettabile. In conclusione, questo caso ha mostrato che operando a velocità prossime alla capacità del canale i pacchetti subiscono un forte ritardo nelle code dei router, prima di essere consegnati a destinazione.
Caso 2: Due trasmettitori e un router con buffer di dimensione finita

In questo secondo caso si ipotizza (1) che la lunghezza del buffer del router sia di dimensione finita e (2) che la connessione sia affidabile.
La conseguenza della prima assunzione è che quando un pacchetto arriva in una coda piena si può verificare una sovrascrittura di pacchetti, o un rifiuto ad accettare il pacchetto. La seconda ipotesi, invece, assume che se un pacchetto si perde perchè il router non lo memorizza, il trasmettitore lo ripete. Di conseguenza bisogna precisare che il termine velocità di trasmissione si riferisce alla velocità λin (byte/sec) dei byte consegnati dal processo applicativo al processo TCP. La velocità con cui il livello trasporto invia i dati sul canale, che comprendono sia i dati originati dal processo applicativo sia i dati ripetuti, verrà indicata con λ'in byte/sec.
λ'in è anche denominata occupazione del canale.
Le prestazioni raggiunte in questo caso 2 dipendono esclusivamente dalle ritrasmissioni. Prima si ipotizzi che A sia in grado di prevedere se il buffer del router è libero e quindi possa decidere se inviare un pacchetto o aspettare che il buffer sia libero. In questo caso, quindi, non dovrebbe mai avvenire la perdita di segmenti per sovrascrittura o per rifiuto del router ad accettare nuovi pacchetti, λin dovrebbe essere uguale a λ'in, e il flusso sulla connessione dovrebbe essere uguale a λin.Dal punto di vista del flusso, le prestazioni sono ottimali - tutti i byte inviati vengono ricevuti. Notare che la velocità media di trasmissione non può superare R/2, perchè si è assunto che non ci sia perdita di pacchetti.
Si consideri che il mittente ritrasmetta solo quando è sicuro che un pacchetto si è perso (questa assunzione è basata sul fatto che il mittente possa impostare i suoi timer con un intervallo sufficientemente grande da poter ritenere che se non arriva l'ACK il pacchetto si è perso). In questo caso, le prestazioni degradano. Per comprendere ciò, si supponga che il carico offerto al canale, λ'in (la velocità dei dati più quelli ritrasmessi), sia R/2. A questo valore di occupazione del canale, la velocità a cui i dati vengono consegnati al processo applicativo del ricevitore è (ad esempio) R/3. Così delle 0.5·R unità di dati trasmessi, 0.333·R byte/sec (in media) sono dati utili e 0.166·R byte per secondo (in media) sono dati ripetuti. Si può così individuare un altro costo della congestione della rete - Il trasmettitore deve ripetere i segmenti inviati allo scopo di recuperare i pacchetti perduti per buffer overflow.
Infine si consideri il caso più realistico in cui si verifica il timeout al mittente e il pacchetto, che non si è perso, ma è ritardato nella coda, viene ripetuto. In questo caso, entrambi i pacchetti, quello in ritardo e quello ripetuto, raggiungono il ricevitore. Naturalmente, il ricevitore scarta il pacchetto duplicato. In questo caso il router è stato impegnato inutilmente a smistare una copia del pacchetto. Il router avrebbe potuto sfruttare meglio il canale inviando un pacchetto utile. Questo è un altro costo della congestione della rete - la trasmissione di un pacchetto duplicato costringe il router a sprecare l'occupazione del canale. Poichè ogni pacchetto è inviato due volte, il flusso sarà limitato superiormente da R/4, quando il carico offerto alla rete approssima R/2.
Caso 3: Quattro mittenti, router con buffer finiti e percorsi con più router
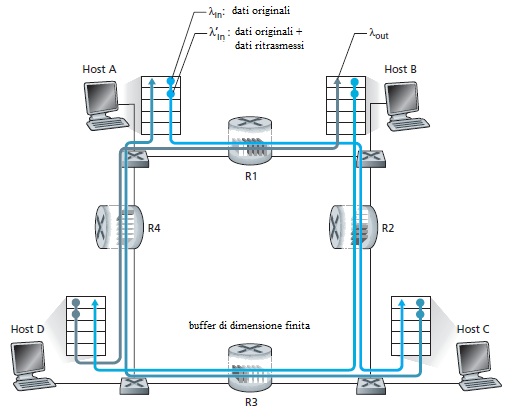
Come ultimo caso si consideri di avere quattro host che inviano pacchetti, e che su ogni canale si sovrappongano due connessioni come in Figura. Si assuma anche che ogni host usi un meccanismo di timeout/ritrasmissione per implementare un servizio di trasferimento affidabile, che tutti gli host abbiano lo stesso valore di λin, e che tutti i canali abbiano la capacità R byte/sec.
Si consideri che la connessione dall'Host A all'Host C, passi attraverso i router R1 ed R2. La connessione A-C condivide il router R1 con la connessione D-B e condivide il router R2 con la connessione B-D. Per valori estremamente piccoli di λin, i buffer overflow sono rari (come nei casi di congestione 1 e 2), e il flusso uguaglia approssimativamente il carico offerto al canale. Per valori leggermente più grandi di λin, anche il flusso dei pacchetti consegnati cresce. In queste condizioni, (λin <R/2), ad un incremento di λin si osserva un incremento di λout.
Avendo considerato il caso di traffico estremamente basso, si consideri adesso che λin (e quindi λ'in) sia estremamente grande. Si consideri il router R2. Il traffico A-C che arriva al router R2 (proveniente da R1) può giungere ad una velocità che è al massimo R, la capacità del canale da R1 a R2, senza tener conto del valore di λin. Se λ'in è molto grande per tutte le connessioni (inclusa la connessione B-D), allora la velocità del traffico della connessione B-D che arriva su R2 può essere molto più elevata del traffico sulla connessione A-C. Poichè il traffico delle due connessioni A-C e B-D deve giungere al router R2 e qui i pacchetti competono per occupare uno spazio limitato nel buffer, il traffico di A-C che riesce a passare attraverso R2 (cioè non subisce perdite per sovrascrittura) si riduce sempre di più quando il carico offerto dalla connessione B-D cresce. Al limite quando il carico offerto tende a infinito, un buffer vuoto in R2 viene rapidamente riempito dai pacchetti B-D e il flusso sulla connessione A-C in R2 tende zero. Di conseguenza, il flusso sulla connessione A-C tende a zero in presenza di traffico intenso.
La ragione di una eventuale diminuzione del flusso al crescere del carico offerto è evidente quando si considera la quantità di lavoro inutile compiuto dalla rete. Nel caso di traffico intenso, ogni volta che un pacchetto viene rifiutato dal secondo router sul percorso tra due host, il lavoro del primo router, per instradare un pacchetto verso il secondo, è stato sprecato. Sarebbe stato meglio se il primo router avesse scartato il pacchetto, rimanendo inoperoso. La capacità di trasmissione usata dal primo router per instradare il pacchetto al secondo router sarebbe stata sfruttata più proficuamente per trasmettere un pacchetto diverso. Ad esempio, un router potrebbe dare la priorità ai pacchetti che hanno già attraversato molti router.
Si incontra così un altro costo della congestione: - quando si perde un pacchetto lungo il cammino, la capacità di trasmissione che era stata sfruttata dai router per smistare il pacchetto fino al punto in cui viene perso, è stata sprecata.
il controllo della Congestione
Esistono due tecniche per contrastare il fenomeno della congestione, e in questa sezione si discuterà come il protocollo può prevenire la congestione.
Anche il processo del livello rete può (nell'architettura ATM) collaborare con il livello trasporto per introdurre un controllo della congestione.
Controllo della congestione end-to-end. Il livello rete non fornisce un'assistenza esplicita al livello trasporto per controllare la congestione, La presenza della congestione nella rete può essere intuita dal sistema terminale osservando il ritardo con cui viaggiano i pacchetti di conferma o con la necessità di ripetere pacchetti persi. Il TCP non ha altro modo di controllare la congestione perchè il livello IP non offre un riscontro al sistema terminale relativamente all'intensità del traffico sulla rete. La perdita di un segmento TCP (indicata da un timeout o da una tripla conferma) è interpretata come una indicazione di congestione e, di conseguenza, il TCP riduce la dimensione della sua finestra. Il TCP usa l'intervallo di tempo tra l'istante della trasmissione di un pacchetto e l'istante di ricezione della sua conferma per osservare l'approssimarsi ad una situazione di congestione.
Controllo della congestione assistito. In alcune architetture di rete, i router forniscono delle indicazioni sullo stato della congestione ai trasmettitori. Questa soluzione fu adottata nelle architetture SNA e DECnet. Esistono anche controlli più sofisticati. Ad esempio un router potrebbe specificare al trasmettitore anche la massima velocità che è in grado di mantenere su un canale di uscita.
Per il controllo assistito della congestione, ci sono due modi per inviare l'informazione al trasmettitore. Una informazione diretta dal router al mittente, consistente in un pacchetto che avverte che il router è congestionato, e una forma di notifica inserita nei pacchetti in transito dal mittente al destinatario, che verrà poi inviata al mittente nei pacchetti di risposta.
Controllo della Congestione in TCP
Il TCP fornisce un servizio di trasporto affidabile tra due processi in esecuzione su due host diversi. Il controllo della congestione è un componente del TCP. Il TCP deve usare un controllo della congestione end-to-end non potendosi affidare alla rete per ottenere collaborazione, perchè il livello rete non fornisce nessuna informazione agli end system relativamente allo stato di congestione della rete.
L'approccio del TCP è quello di regolare la velocità a cui il mittente può inviare pacchetti sulle sue connessioni in funzione della congestione percepita. Se un mittente TCP rileva l'assenza di congestione sul percorso tra sé stesso e il destinatario aumenta la frequenza dei pacchetti trasmessi. Se il mittente sospetta la presenza di congestione lungo il percorso, riduce la frequenza di trasmissione dei pacchetti. Ma questa soluzione introduce tre problemi: Primo, come può fare il TCP mittente a ridurre il traffico sulle sue connessioni? Secondo, in che modo il TCP mittente riconosce la presenza della congestione lungo il percorso verso il destinatario? Terzo, quale algoritmo usare per calcolare la variazione della frequenza dei pacchetti trasmessi?
Si esamini prima come un mittente TCP può limitare la velocità a cui immette traffico sulla sua connessione. Si ricordi che ogni connessione TCP consiste di un buffer al ricevitore, un buffer al mittente e alcune variabili. Il meccanismo di controllo della congestione che opera a livello mittente, gestisce un'altra variabile: la finestra di congestione.
La finestra di congestione, indicata con cwnd impone un vincolo sulla velocità con cui il TCP mittente può inviare traffico nella rete.
Più in particolare, la quantità di pacchetti non confermati al mittente non deve superare il minimo valore tra cwnd e rwnd, cioè:
LastByteSent - LastByteAcked <= min{cwnd, rwnd}
Per analizzare il problema del controllo della congestione (non il controllo del flusso) si assuma che il buffer del ricevitore sia abbastanza grande da poter trascurare il vincolo imposto sulla finestra del ricevitore, così il numero di dati non confermati al mittente è limitato solo da cwnd. Si assuma, inoltre, che il mittente abbia sempre dati da inviare, cioè tutti i segmenti che rientrano nella finestra di congestione vengono trasmessi.
Il vincolo così introdotto limita la quantità di dati non confermati che il mittente non deve superare. Indirettamente, questo significa che viene limitata la velocità di trasmissione del mittente. Infatti si consideri una connessione su cui le perdite di pacchetti e i ritardi di consegna siano trascurabili. Si può ritenere che, approssimativamente, all'inizio di un RTT il vincolo impone al trasmettitore di inviare cwnd byte sulla connessione. Entro la fine dell'intervallo RTT il mittente riceve le conferme di tutti i dati consegnati. Si può stimare che la velocità di trasmissione del mittente sia: cwnd/RTT byte/sec. Modificando il valore di cwnd, il mittente regola la velocità con cui può inviare dati sulla connessione.
Quali sono gli indizi che permettono al TCP di percepire la presenza di una canale congestionato tra sé stesso e la destinazione? Si definisce l'evento perdita di un pacchetto, generato al TCP dal lato del mittente, come il verificarsi di un timeout o la ricezione di tre ACK per uno stesso segmento. In presenza di un traffico elevato, i buffer di uno o più router sono pieni e quei router scartano i pacchetti (contenenti segmenti del TCP). Il pacchetto scartato provoca il verificarsi dell'evento perdita di un pacchetto al mittente (timeout o tre ACK ripetuti), che viene usato come indicatore di presenza di un canale congestionato tra mittente e destinatario.
Dopo aver deciso con quale criterio viene riconosciuta una congestione della rete, si supponga di trovarsi in una situazione in cui i canali della rete non sono congestionati, cioè non si verifica mai un evento perdita di un pacchetto. In questo caso, il TCP mittente riceve tutte le conferme dei pacchetti trasmessi. Il TCP mittente considera che queste conferme rappresentino l'indicazione di un corretto funzionamento della comunicazione, cioè tutti i pacchetti trasmessi sono stati consegnati al destinatario, ed userà queste conferme per allargare la sua finestra di congestione (e di conseguenza la sua velocità di trasmissione). Notare che se le conferme arrivano a bassa velocità (ad esempio perchè c'è un canale con capacità bassa) anche la finestra di congestione sarà allargata lentamente. In altri termini, se le conferme arrivano ad alta velocità la finestra di congestione verrà allargata rapidamente.
Dopo aver determinato il criterio per regolare il valore di cwnd allo scopo di controllare la velocità del trasmettitore, resta la questione: come può un mittente TCP calcolare la velocità di trasmissione? Se tutti insieme i mittenti TCP trasmettono troppo velocemente, possono congestionare la rete, portando la rete al collasso. Nel seguito si farà riferimento ad una delle prime versioni del protocollo di trasporto che fu sviluppata dopo aver osservato un reale collasso di Internet. I mittenti TCP, prudentemente, iniziano a trasmettere a bassa velocità, forse utilizzando parzialmente la banda, cioè i mittenti potrebbero trasmettere più velocemente senza saturare la banda. In altri termini ci si chiede come possono fare i mittenti TCP a sfruttare tutta la banda senza congestionare la rete? Esiste un modo per coordinare i mittenti TCP distribuiti nella rete oppure i mittenti potrebbero disporre di informazioni utili per calcolare la velocità di trasmissione? A queste domande si può rispondere seguendo le seguenti indicazioni:
-
Un segmento perso consente di sospettare che cia un canale congestionato, quindi al verificarsi di un tale evento la velocità di trasmissione del mittente dovrebbe essere diminuita. Bisogna ridimensionare la finestra di congestione del mittente per costringerlo a rallentare.
Un segmento confermato indica che la rete sta consegnando i pacchetti trasmessi al ricevitore e quindi la velocità può essere aumentata in corrispondenza di un ACK. L'arrivo delle conferme viene interpretata come una indicazione implicita che la rete non è congestionata. La finestra di congestione può essere allargata.
Sondaggio della banda. Visto che la ricezione degli ACK indica che il cammino tra mittente e destinatario non è congestionato, e che la perdita di pacchetti fa sospettare che la rete porrebbe essere congestionata, La strategia del TCP è quella di aumentare la velocità di trasmissione in risposta agli ACK ricevuti fino a quando si verifica la perdita di un segmento. A questo punto la velocità di trasmissione viene diminuita. In pratica, il mittente aumenta la velocità di trasmissione per valutare il punto in cui inizia la congestione. riduce la velocità e riprende a sondare per vedere se la congestione si manifesta ancora. Notare che non esiste una segnalazione esplicita, da parte delle apparecchiature di rete, dello stato di congestione, ma si usano osservazioni sulle perdite o sulle conferme dei pacchetti per valutare lo stato della rete. Queste informazioni sono ottenute da ciascun mittente in forma autonoma, indipendentemente dagli altri mittenti.
Uno dei primi algoritmi per controllare la congestione è organizzato in tre componenti: (1) slow start; (2) prevenzione della congestione, e (3) recupero rapido. La parte Slow start e la parte congestion avoidance sono componenti obbligatorie del TCP, differiscono per il metodo con cui calcolano la dimensione della finestra cwnd in conseguenza degli ACK ricevuti. La parte Fast recovery non è richiesta, ma è consigliata.
Slow Start
Quando si inizia a trasmettere su una connessione TCP, si usa un valore iniziale di cwnd molto piccolo, ad esempio 1 MSS (Maximum Segment Size), che corrisponde ad una velocità di trasmissione, approssimativa, di MSS/RTT. Ad esempio se MSS = 500 byte e RTT = 200 msec, la velocità iniziale di trasmissione è di circa 20 kbps. Siccome la banda disponibile al mittente potrebbe essere un po' di più di MSS/RTT, il TCP mittente prova a calcolare anche il margine a disposizione, in tempi rapidi. Così, nella fase Slow Start, il valore di cwnd inizia da 1 MSS e cresce di 1 MSS ogni volta che che viene confermato un segmento trasmesso. Ad esempio, il TCP invia il primo segmento in rete ed aspetta di ricevere una conferma. Quando arriva questa conferma, il TCP mittente allarga la finestra di congestione di 1 MSS e manda due segmenti di MSS byte. Se anche questi segmenti sono confermati, il mittente allarga la finestra di congestione di 1 MSS per ognuno dei segmenti confermati, allargando la finestra di congestione a 4 MSS, e così via. Questo processo Slow Start provoca un raddoppio della velocità di trasmissione ogni RTT sec. Cioè il TCP inizia con una velocità bassa, ma poi aumenta la velocità di trasmissione in modo esponenziale.
Ma quando dovrebbe finire questa crescita esponenziale? L'algoritmo Slow start prevede tre modi: Primo, se si verifica un evento perdita di un pacchetto (forse provocato dalla congestione) segnalato dal timeout, il TCP mittente porta il valore di cwnd a 1 e ricomincia la fase di Slow Start. In questo caso però il TCP assegna un valore anche ad una nuova variabile: ssthresh=cwnd/2 (ssthresh è l'abbreviazione di "slow start threshold"), cioè a metà del valore di larghezza della finestra di congestione, quando viene rilevata una possibile congestione. Il secondo modo in cui slow start può terminare la crescita esponenziale della velocità di trasmissione è direttamente collegato al valore della variabile ssthresh. Poichè quando viene riconosciuta la congestione, il valore di ssthresh è metà di cwnd, potrebbe essere rischioso continuare a raddoppiare cwnd quando raggiunge o supera il valore di ssthresh. Così, quando il valore di cwnd diventa uguale a ssthresh, la fase slow start termina e il TCP passa nella fase congestion avoidance. In questa fase, il TCP incrementa cwnd con precauzione. L'ultimo modo in cui slow start termina si ha quando vengono ricevuti tre ACK ripetuti, nel qual caso, il TCP esegue una ritrasmissione ed entra nella fase fast recovery.
Congestion Avoidance
Appena si entra nella fase congestion-avoidance, il valore di cwnd è approssimativamente metà del valore che aveva prima di incontrare la congestione. Il TCP presume che il rischio di congestione sia molto elevato. Quindi, anzichè raddoppiare il valore di cwnd ogni RTT sec, il TCP adotta un approccio più prudente ed incrementa il valore di cwnd solo di MSS byte ogni RTT sec. Questa operazione può essere eseguita in vari modi. Il più comune consiste nel far aumentare, al TCP mittente, cwnd di MSS byte (MSS/cwnd) ogni volta che arriva una nuova conferma. Ad esempio, se MSS è 1,460 byte e cwnd è 14,600 byte, allora vengono inviati 10 segmenti in RTT sec. Ogni volta che arriva un ACK (assumendo un ACK per segmento) la finestra di congestione viene allargata di 1/10 di MSS, quindi la finestra di congestione risulterà allargata di 1 MSS dopo che sono stati ricvuti i 10 segmenti ACK.
Ma questa fase di crescita lineare della finestra di congestione (di 1 MSS per RTT) quando dovrebbe terminare? L'algoritmo congestion-avoidance si comporta come se si fosse verificato un timeout. Analogamente alla fase slow start: il valore di cwnd è posto uguale a 1 MSS, e il valore di ssthresh è aggiornato alla metà del valore di cwnd quando si verifica un evento perdita di un pacchetto Si ricordi che un evento perdita di un pacchetto può essere generato anche dalla ricezione di tre ACK ripetuti. In questo caso, la rete sta continuando a consegnare i pacchetti inviati dal mittente al destinatario (altrimenti il ricevitore non avrebbe ripetuto le conferme). Quindi il comportamento del TCP per questo tipo di evento dovrebbe essere meno drastico di quello dovuto ad un timeout: il TCP dimezza il valore di cwnd (aggiungendo 3 MSS byte, in considerazione dei 3 ACK ripetuti) e registra il valore di ssthresh alla metà del valore di cwnd quando riceve tre conferme per lo stesso segmento. Si passa adesso nella fase fast-recovery.
Fast Recovery
Nella fase fast recovery, il valore di cwnd viene aumentato di 1 MSS per ogni ACK duplicato che si riceve, cioè per ogni segmento mancante per cui il TCP era entrato nella fase di fast recovery. Eventualmente, quando arriva un ACK per un segmento mancante, il TCP entra nella fase congestion-avoidance dopo aver ridotto la larghezza della finestra cwnd. Se si verifica un evento timeout, dalla fase fast recovery si passa alla fase slow-start dopo aver compiuto le stesse azioni come in slow start e in congestion avoidance: il valore di cwnd è posto uguale ad 1 MSS, e il valore di ssthresh viene portato alla metà di cwnd quando si verifica l'evento perdita di un pacchetto.
Il componente Fast recovery di TCP è raccomandato, ma non obbligatorio. Le più recenti versioni del TCP incorporano l'algoritmo fast recovery.
Riepilogo del Controllo della Congestione in TCP
Avendo esaminato in dettaglio slow start, congestion avoidance, e fast recovery si può rivedere il comportamento del TCP nella sua interezza. Ignorando la fase iniziale di slow-start, quando si inizia ad usare una connessione, ed assumendo che le perdite di pacchetti vengono indicate da tre ACK ripetuti, anzichè dai timeout, il controllo della congestione del TCP consiste in una crescita lineare (additiva) di cwnd di 1 MSS per RTT e del dimezzamento (diminuzione moltiplicativa) di cwnd in corrispondenza degli eventi tre ACK ripetuti. Per questo motivo, il controllo della congestione del TCP è descritto come una forma con crescita additiva, diminuzione moltiplicativa. Il grafico della dimensione della finestra di congestione in funzione del tempo ha una forma a dente di sega, intuita anche dalla precedente descrizione del sondaggio della banda (il TCP aumenta la frequenza di trasmissione allargando linearmente la finestra di congestione fino a quando si verifica l'evento di 3 ACK ripetuti, a questo punto riduce la larghezza della finestra di congestione di un fattore due e riprende la crescita lineare per provare a sfruttare ancora un margine di banda.
Esistono alcune varianti alle implementazioni del controllo della congestione da parte del TCP. La versione TCP Vegas prova a prevenire la congestione pur ottimizzando il flusso. Questa versione si basa sulle seguenti idee: (1) riconoscere la congestione nei router tra sorgente e destinazione, prima che il pacchetto venga scartato da qualche altro router; (2) abbassare linearmente la velocità di trasmissione nell'imminenza della perdita di un pacchetto. L'imminenza può essere intuita osservando l'RTT. Maggiore sarà l'RTT, maggiore sarà la probabilità che si perda un pacchetto.
Il flusso del TCP
Dato che la finestra di congestione ha un andamento a dente di segna, è spontaneo considerare qual è il flusso medio (cioè la velocità media) su una connessione che porta molti dati. Si trascurerà la fase di slow start che dovrebbe essere svolta dopo ogni evento timeout. (Queste fasi durano poco, a causa della crescita esponenzialmente veloce).
Durante un particolare intervallo round-trip, la velocità a cui il TCP invia dati è una funzione lineare della finestra di congestione e dell'RTT misurato. Quando la dimensione della finestra è w byte ed il round-trip time è RTT secondi, allora la velocità di trasmissine del TCP è approssimativamente w/RTT. Il TCP allora prova a vedere se può sfruttare ancora un po' di banda incrementando w di 1 MSS ogni RTT sec fino a quando si verifica la perdita di un pacchetto. Si indichi con W il valore di w quando si verifica questo evento. Assumendo che RTT e W restano quasi costanti per la durata della connessione, la velocità di trasmissione del TCP varia da W/(2·RTT) a W/RTT.
Queste assunzioni portano ad un modello semplificato del TCP. La rete scarta i pacchetti di una connessione quando la velocità cresce a W/RTT; la velocità allora viene tagliata della metà e viene fatta crescere di MSS/RTT byte/sec ogni RTT fino a quando raggiunge nuovamente W/RTT. Questo processo si ripete. Poichè il flusso del TCP (cioè la velocità di trasmissione) cresce linearlmente tra i due valori estremi, si ha:
flusso medio su una connessione è = (0.75·W)/RTT
Il TCP su canali a banda larga
Il TCP progettato quando la rete Internet era usata per applicazioni quali posta elettronica, terminale virtuale ecc, non è adeguato per le moderne reti ad alta velocità, in cui vengono offerti sempre nuovi servizi e nascono i grid-computer e il cloud computer.
Ad esempio si consideri una connessione TCP con segmenti di 1500 byte e RTT di 10 ms. Si supponga di voler trasmettere dati sulla connessione alla velocità di 10 Gbps. Applicando la formula per il calcolo del flusso, per raggiungere un flusso di 10 Gbps la finestra di congestione dovrebbe essere larga 83.333 segmenti. Ma sicuramente molti di questi pacchetti si perderanno nella rete. È stato stimato che, nelle moderne reti, per raggiungere la velocità di 10 Gbps, un algoritmo di controllo della congestione può tollerare la perdita di un pacchetto con probabilità 2·10-10 o equivalentemente un segmento ogni 5.000.000.000 di segmenti.
Equità
Si supponga di avere K connessioni TCP, ognuna con un diverso percorso tra sistemi terminali, ma tutte costrette ad attraversare uno stesso canale che ha una capacità R bps. Si suppone che su ogni connessione stia avvenendo un trasferimento di grandi quantità di dati e che sul canale in comune non ci siano pacchetti UDP. Un meccanismo di controllo della congestione è detto equo se la velocità media di ogni connessione è ripartita in misura uguale R/K. Cioè ogni connessione ottiene la stessa frazione di banda condivisa.
Si consideri il caso più semplice di due connessioni TCP che condividono un canale con capacità R. Si assuma che le due connessioni abbiano gli stessi MSS e RTT (quindi hanno la finestra di congestione della stessa larghezza e, di conseguenza, lo stesso flusso), inoltre i due host hanno una grande quantità di dati da trasmettere e sul canale non passano dati di altre connessioni. Si ignori la fase slow-start del TCP. Se il TCP deve ripartire la banda in misura uguale tra le due connessioni, allora la somma dei due flussi dovrebbe essere uguale a R.
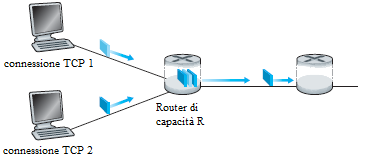 | 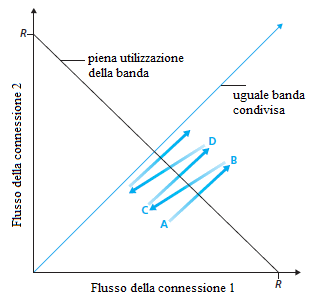 |
Osservando il grafico, lo scopo dovrebbe essere quello di raggiungere un flusso che si trova vicino all'intersezione della retta di uguale sfruttamento della banda e quella di pieno sfruttamento. Ad esempio, se in un certo istante la larghezza della finestra dei due mittenti è tale che le due connessioni trasmettono un flusso che sul grafico è indicato con A, poichè le due connessioni, insieme, utilizzano meno della capacità R del canale, non si verificano perdite di pacchetti ed entrambe le connessioni allargheranno la propria finestra di 1 MSS per RTT, in conseguenza dell'applicazione dell'algoritmo congestion-avoidance. Così il flusso totale delle due connessioni procede lungo una retta inclinata di 45 gradi (crescita uguale per entrambe le connessioni) a partire dal punto A. Potrebbe risultare che la banda consumata dalle due connessioni è maggiore di R, ed eventualmente si perdono anche pacchetti. Se le due connessioni rilevano la perdita di pacchetti mentre stanno trasmettendo alla velocità indicata dal punto B, le due connessioni rallenteranno il flusso dei dati inviati riducendo la larghezza della finestra di un fattore 2. Si realizza quindi il flusso indicato dal punto C. In questa situazione le due connessioni usano una banda minore di R, Le due connessioni, nuovamente, incrementano il loro flusso lungo una retta inclinata di 45 gradi a partire dal punto C. Ci si porta in un nuovo stato D dove si rilevano perdite di pacchetti, e le due connessioni diminuiscono la larghezza della finestra di un fattore 2 e così via.
Bisogna convincersi, da questa discussione, che il flusso delle due connessioni oscilla intorno alla retta di uguale utilizzo della banda fino a convergere all'intersezione delle due rette. Nonostante sia una situazione ideale, si può vedere che il TCP ripartisce equamente la banda tra le connessioni.
Nel precedente esempio ideale, si è assunto che le connessioni attraversano un canale comune, che le connessioni hanno lo stesso valore di RTT e che tra una coppia di host esiste una sola connessione. Nella pratica queste condizioni non sono soddisfatte e le applicazioni client server possono ottenere porzioni diverse di banda. È stato osservato, nella pratica, che, quando più connessioni usano uno stesso canale che costituisce un collo di bottiglia, le sessioni che hanno un RTT piccolo, riescono a spostare la banda disponibile più rapidamente quando il canale diventa libero (cioè allarga la finestra di congestione più rapidamente) e quindi guadagnano un flusso maggiore di quelle che hanno RTT grandi.
Equità e UDP
Il controllo della congestione del TCP regola la velocità di trasmissione delle applicazioni con il meccanismo della finestra di congestione. Le applicazioni multimediali, quali la telefonia su Internet e la video conferenza, non si appoggiano sul TCP, perchè richiedono che il flusso sia costante o, in termini equivalenti, richiedono che il ritardo tra un pacchetto e il successivo si mantenga costante, anche se la rete è congestionata. Queste applicazioni si appoggiano sull'UDP, che non esegue il controllo della congestione. Le applicazioni che si appoggiano sull'UDP inviano i pacchetti audio e video a velocità costante, anche se si perdono pacchetti. Queste applicazioni possono tollerare la perdita di qualche pacchetto.
Le applicazioni che si appoggiano sull'UDP non sono eque, non collaborano con le altre applicazioni nè regolano la velocità di trasmissione. Per questa ragione il traffico UDP può provocare l'interruzione del traffico TCP. Attualmente si sta ricercando un modo per far coesistere il traffico UDP e il traffico TCP.
Equità e connessioni parallele
Anche se si forzasse il traffico UDP a concedere una frazione equa di banda alle altre applicazioni, resta il problema che non si può impedire alle applicazioni di utilizzare connessioni multiple. Ad esempio alcuni browser aprono più connessioni per trasferire tutti gli elementi contenuti in una pagina. In questo modo una applicazione ottiene una banda maggiore. Si pensi ad un canale di capacità R con nove applicazioni client server, ciascuna su una propria connessione. Se si inserisce una nuova applicazione che si appoggia sul TCP, allora ogni applicazione occupa approssimativamente la stessa frazione di banda: R/10. Se, invece, la nuova applicazione usa connessioni TCP parallele, allora questa sfrutta, iniquamente, più di R/2 di banda.